Fine Art Classification using Unsupervised Visual Representation Learning
This work aims to examine the applicability of self-supervised contrastive learning for computer vision within the domain of fine art. We train multiple convolutional neural network architectures apply- ing the momentum contrast framework using images from three fine-art collections. After pre-training the network we further investigate the performance of the learned networks on multiple downstream tasks for each dataset. Lastly we use explainable AI techniques on the learned networks for some of the downstream tasks.
Datasets
In this work we examine three publicly available fine art image datasets, WikiArt, iMet, and Rijksmuseum. In the pre-training phase of this study we discard the labels associated with each image and shuffle the combined datasets. The WikiArt dataset contains photographic reproductions of over 80,000 paintings from 27 different artistic movements. In addition there are over 1,000 unique artists represented. The iMet Collection was released recently in 2019 as part of a Kaggle competition. The collection contains over 100,000 fine-art objects from the Metropolitan Museum of Art. The Rijksmuseum dataset contains a collection of over 100,000 fine-art objects from the Rijksmuseum in Amsterdam. The objects encompass a large variety of different art forms ranging from prints to sculptures. This collection has over 6000 unique artists, over 1000 different art types, and 403 types of materials.
Methodology
For the task of fine art classification we divide our process into two distinct phases, unsupervised pre-training and downstream evaluation. With the unsupervised pre-training we train a convolution neural network on the combined datasets without labels. We then use this network as a feature extractor to then train a classifier for each datasets' supervised tasks.
Unsupervised Pre-Training
The convolution neural networks were pre-trained on the combined training splits of the three datasets. For unsupervised pre-training we use the momentum contrast framework [1]. For each image a randomly resized crop with random horizontal flip of size 128 by 128 was extracted from the image and the augmented using color jitter, gaussian blur, and color drop.
Downstream Supervised Tasks
For downstream evaluation of the learned visual representations for multi-class classification we used a softmax classifier with cross entropy as the loss function on the representations extracted from the frozen convolution network pre-trained using momentum contrast. The extracted representations come from a single crop of size 244 by 244 from the original image.
Results
Quantitative
Compared to other works examining fine art classification we found that our pre-trained models consistently underperformed compared to state of the art models however our model uses unsupervised learning to train a convolutional network and does not utilize fine-tuning or particularly large models. The pretrained networks were most successful on the WikiArt dataset in which they were competitive with transfer learning with networks trained on ImageNet in [2].
Filter Visualizations
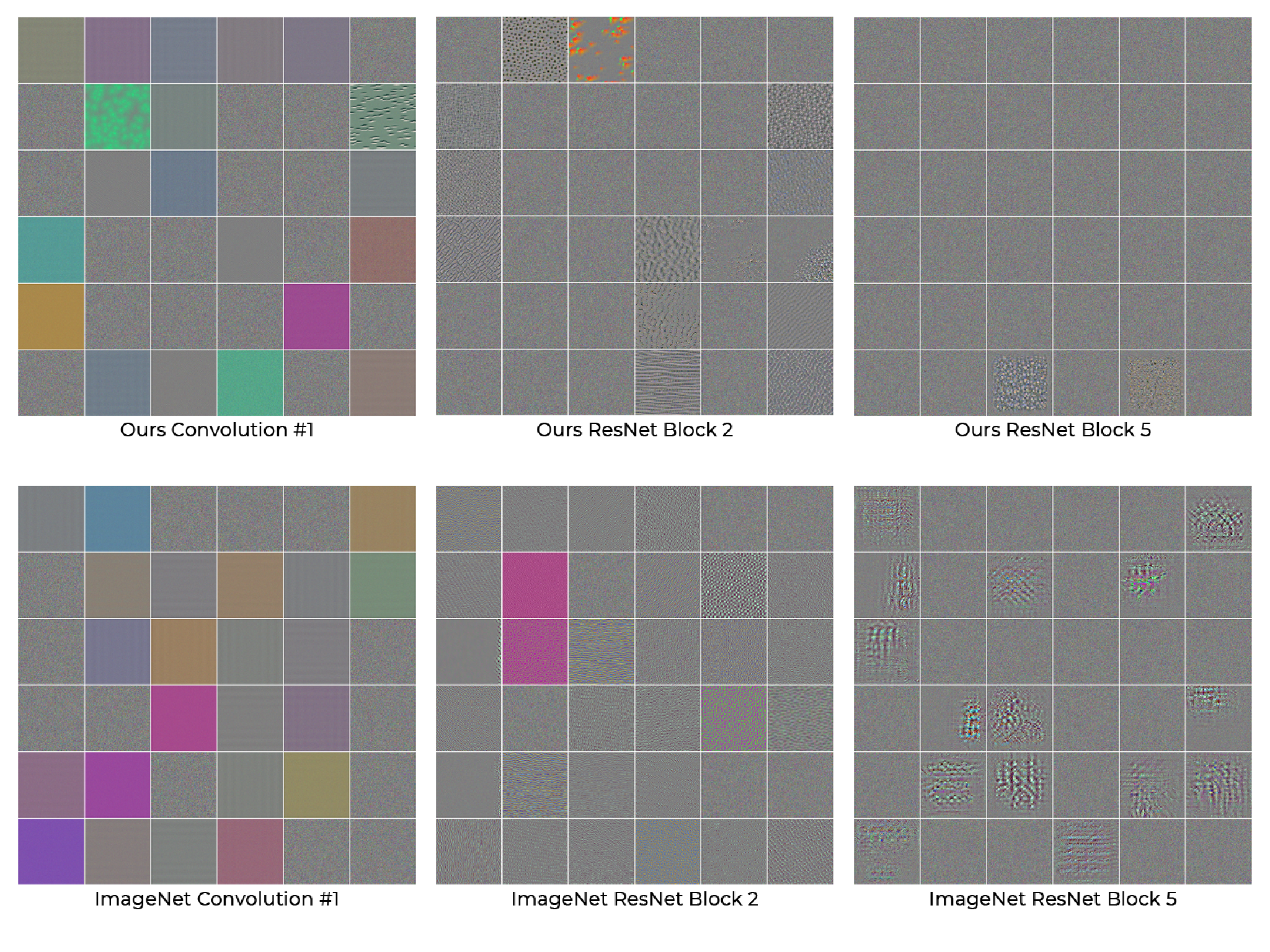
In addition to our quantitative results obtained from our multiple downstream tasks, we use filter visualization to examine what features the models learn from the contrastive learning pretext task. In the image below we can see a random selection of the learned filter from the contrastive learning task on our dataset. Comparing the filters at the shallowest portion of the network (Convolution #1) we see that both tend to learn filters for various colors while in the case of the contrastive learning network we also see the addition of some simple textures start to appear. We can also see from this comparison that there appear to be fewer non-noise filters with the contrastive learning model compared to the ImageNet model particularly in the deeper levels of the network.
Explainable AI
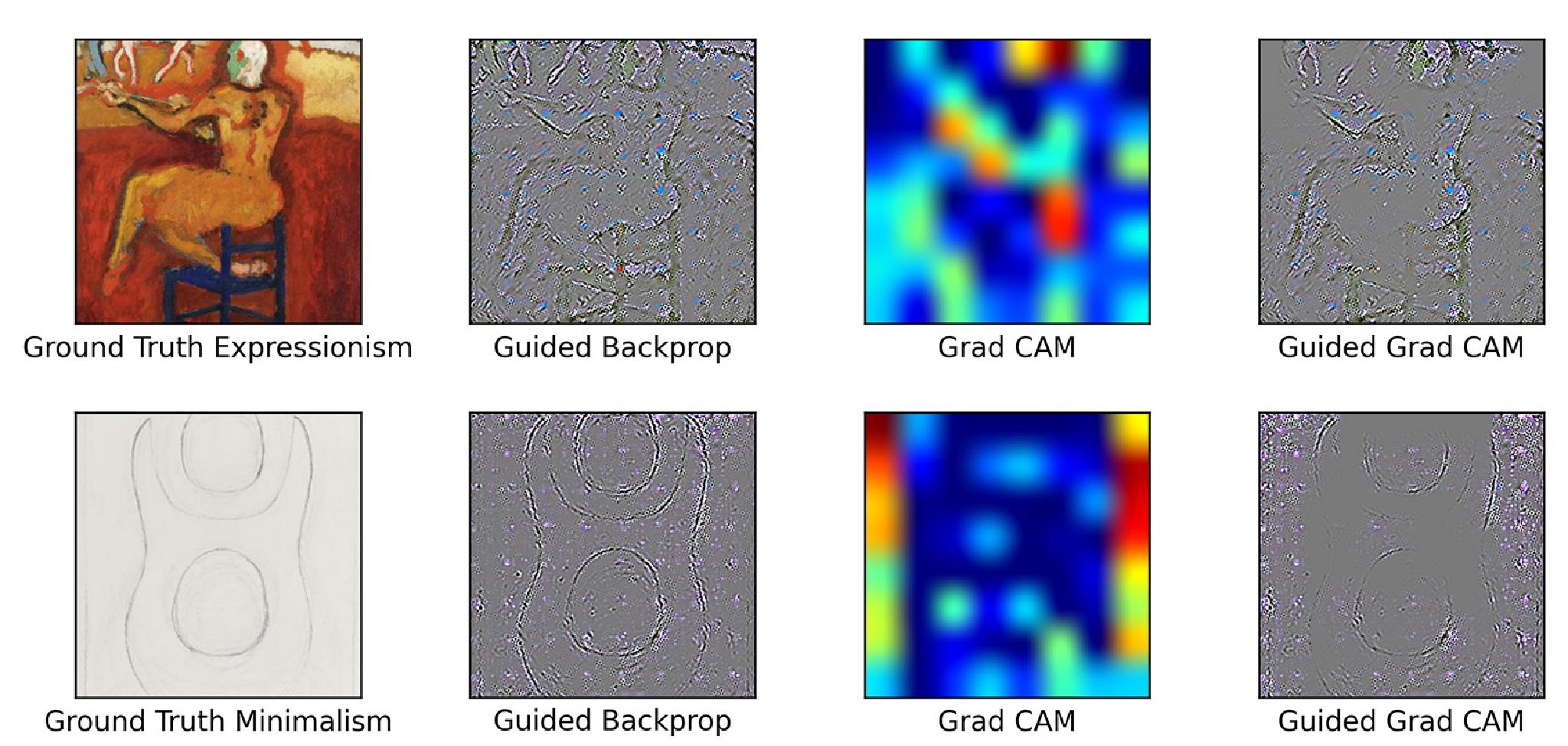
In addition to examining how the self-supervised models perform on our selected downstream task, we additionally use explainable AI techniques to bet- ter understand how these self-supervised models justify their decisions. In this vein we use a combination of two techniques proposed by Selvaraju et. al which include guided backpropagation and class activation maps [3]. In particular we examine the two classification tasks of artist recognition and art style classification for the WikiArt dataset using a linear classification head on top of the pre-trained convolutional neural network. For our convolutional model we chose to use our pre-trained ResNet50 trained for 120k steps.
References
[1] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” arXiv preprint arXiv:1911.05722, 2019.
[2] W. R. Tan, C. S. Chan, H. E. Aguirre, and K. Tanaka, “Ceci n’est pas une pipe: A deep convolutional network for fine-art paintings classification,” in 2016 IEEE International Conference on Image Processing (ICIP), pp. 3703– 3707, 2016.
[3] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” International Journal of Computer Vision, vol. 128, p. 336–359, Oct 2019.